


Predicting PHQ-9 Depression Scores from Multi-Clinic EHR Data
Predicting depression severity from routine EHR data.
The problem
Measuring depression severity normally needs a separate PHQ-9 visit, so patients often get flagged late.
My contribution
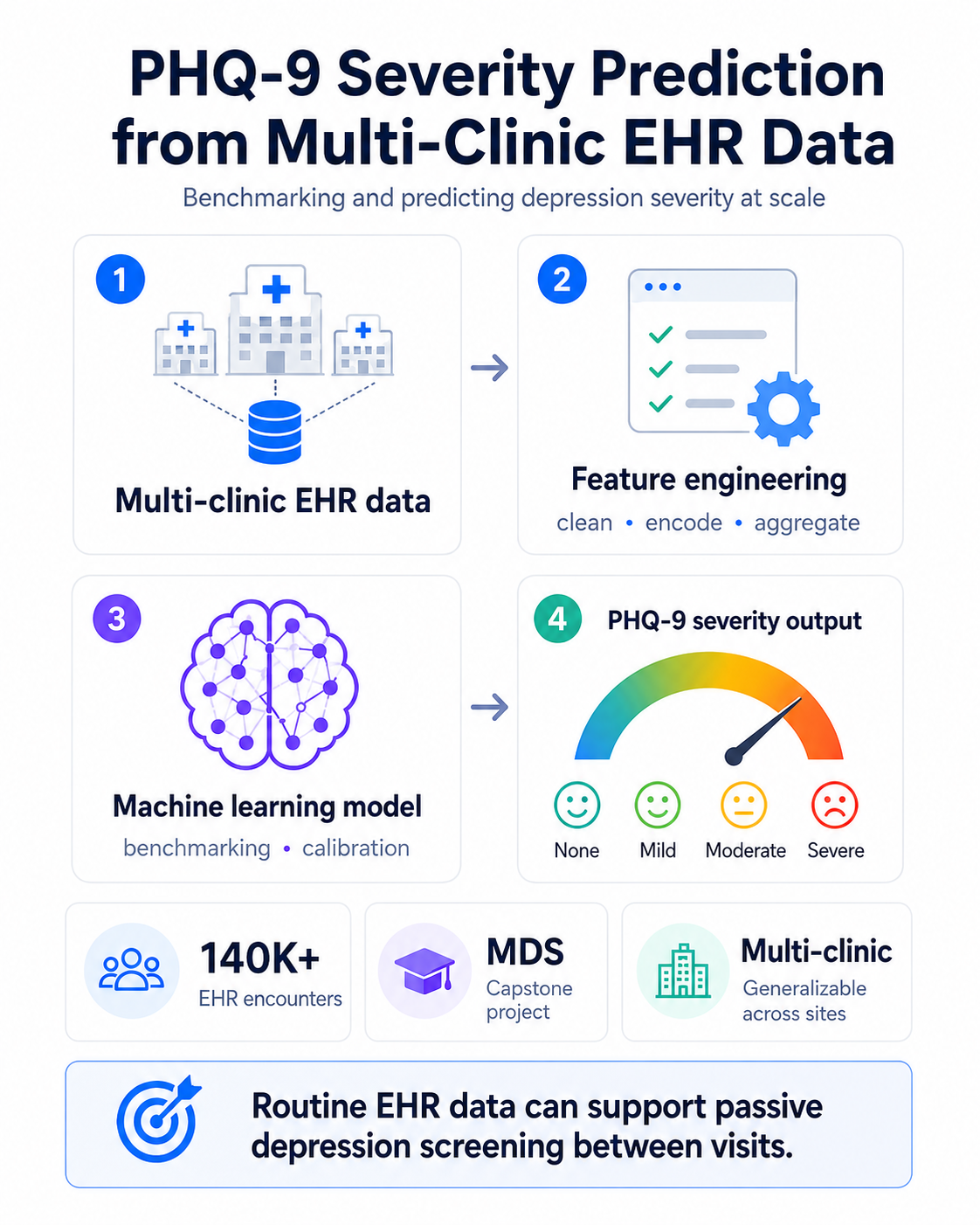
Led a UBC MDS capstone for GreenspaceHealth: engineered features from 140K+ multi-clinic encounters and built a calibrated, explainable model that predicts PHQ-9 severity without the questionnaire.
Outcome
Shipped a deployable model with feature-importance reports — showing routine EHR data alone can flag depression between visits.
What I learned
Held-out splits matter more than model architecture in clinical ML — the early Random Forest looked deceptively strong until the validation strategy switched from held-out visits to held-out patients. The biggest practical win was investing in the data pipeline before the model: most of the accuracy gain came from feature engineering on the warehouse side, not from the temporal architecture itself.
- Type
- Model
- Role
- Capstone · ML lead, team of 2
- Timeframe
- May — Jul 2024
- Stack
-
PythonSnowflake SQLscikit-learnpandasRandom ForestTemporal Neural Network
- Tags
-
HealthMLPredictive modelingEHR